Защо персоналът на телугу се е блъскал в устройства на Apple
Apple има няколко месеца бъги. Сега имаме нов, сериозен проблем в функционалността на текстовото рендиране в iPhone. Проблемът се задейства от единичен символ на Telugu, който може да накара iPhone да влезе в нечуплив ботушен цикъл само с получаването на известие, съдържащо знака. Нека да разгледаме защо един единствен знак може да причини такива големи проблеми с iOS.
Забележка: Корекция на грешката на Telugu е налична в най-новата версия на iOS (11.2.6). Ако знакът на Telugu е заключил вашето приложение или устройство, възстановете своя iPhone чрез iTunes и актуализирайте до най-новата версия на iOS. Ако вашият iPhone е заседнал в запушалка, може да се наложи да го поставите в състояние Update Device Firmware (DFU), за да накарате iTunes да го разпознае. Когато приключите, възстановете устройството си от най-новото си резервно копие, което, надявам се, е създадено.
Какво е Telugu?

Телугу е език, говорен и написан в някои части на Индия, по-специално в щатите Андхра Прадеш, Телангана и в град Янам. Подобно на много скриптови езици, като например арабски и други брахмически скриптове, Telugu използва някои специални функции на набора от символи на Unicode, за да показва знаците си на компютърния екран.
Макар че повечето латински букви се представят от единична 8-битова кодова точка Unicode за ASCII съвместимост (например буквата А съществува в Unicode кодовата точка U+0041, която е представена в двоичен 01000001 ), езици, написани със скрипт или не- Латинските букви обикновено съчетават повече от една Unicode кодова точка, за да представят своите знаци.
Това важи особено за езиците като Telugu, които комбинират езиковите версии на буквите в клъстерите. За разлика от стилистичните лигатури на английски език, връзката между всяко писмо в Telugu е от езиково значение. За да се приспособи към това, Unicode включва сложна система за прикрепване на символи, всяка от които представлява тяхната собствена кодова точка, един към друг.
Като се има предвид пълния брой на Unicode кодовите точки, това може да създаде почти безкраен сорт. Тези точки се комбинират, за да дадат четлив характер. По този начин Unicode не се нуждае от Unicode кодова точка за буквално всяка възможна дума на Телугу. Вместо това, Unicode съчетава конглонти на Telugu, гласни и diacritice ("virama") заедно, за да създават думи, които се показват като един знак. Същото важи и за други езици с ортографски правила за лигатури, като арабски.
Какво причинява катастрофата?

Проблемът изглежда е свързан с безжичната машина с нулева ширина (ZWNJ) в кодова точка U+200C . ZWNJ изисква два съседни символа да се правят без типичната си лигатура. На английски език, ZWNJ запазва знаците ff от отпечатване със стандартната си лигатура за връзка, вместо да отделя всеки f. Но когато се комбинира с конкретен набор от четири точки на код Telugu (всички от които трябва да се комбинират с един клъстер), поради някаква причина iOS не може да покаже резултата правилно.
Някои смятат, че шрифтът на Apple в Сан Франциско не може да покаже характера, докато други казаха, че е виновен специфичният процес на рендиране, използван от Apple. Каквато и да е каквато и да е причината, опитът да се направи характерът причинява драматичен срив на всичко, което го прави, от Messages и WhatsApp до Springboard. Кодовете на Unicode, които съставляват героя ("gya" означава "знание") са по-долу:
U+0C1Cja (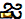 )
)U+0C4Dвирама или знак за знак ( )
)U+0C1Enya (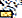 )
)U+200Cнулева ширина, които не са свързаниU+0C3Eaa (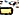 )
)
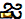 )
) )
) )
) )
)Но ние дори не можем да обвиняваме Нуроусинхронизатора с нулева ширина (ZWNJ) сам. Той се използва и в безобидните семейни емози (????) без никакъв проблем. Изглежда, че е специфична комбинация от някои специфични кодови точки и ZWNJ. Като добавим обида към нараняване, изглежда, че ZWNJ няма конкретен ефект върху представянето на този клъстер на Telugu или че дори не трябва да бъде там на първо място.
Други проблеми с Брахмическия скрипт
Телугу не е единственият език по този въпрос. Бенгали и Деванагари, които използват Уникод по подобен начин за своите брамически сценарии, имат същия проблем. Manish Goregaokar пише подробна и подробна публикация в блога, която разбива още по-точно случая с катастрофата:
Всяка последователност
в Devanagari, Bengali и Telugu, където:1.
consonant2е суфикс-свързваща (pstf/vatu)
2.consonant1не е буквено писмо
3.vowelняма две глифови компоненти
Заключение: Защо не беше хваната от Apple?
За да разберете как е станало това бъг, трябва да се поставите в обувките на Apple. Разбира се, тази комбинация от знаци не е някаква супер неясна дума на езика на Телугу. IPhone обаче включва поддръжка на десетки езици. Има буквално милиарди потенциални комбинации в Unicode. С толкова много разнообразие, смисленото тестване за програмни грешки от Unicode преди издаването би направило практически невъзможно редовното актуализиране на софтуера.
Грешката обаче не би трябвало да причини толкова много щети. Телефоните не трябва да се заглушават въз основа на съдържанието на текстово съобщение. Докато гледането назад със сигурност е 20/20, изглежда, че да направиш знака като кутия за въпросителни въпроси ( ) би бил по-добър от сривът на Springboard.

![Забележка - Забележка Като просто начин [Mac]](http://moc9.com/img/noted-quick-intro.jpg)


![Мислите ли, че децата (под 12) трябва да носят смартфон? [Анкета]](http://moc9.com/img/poll-result-ios7-innovative.png)

